Introduction
Latitude is an open-source agent observability platform. It helps teams turn live agent traffic and human judgment into measurable, improvable quality. So you can ship AI features with confidence.What Latitude Does
Latitude gives you a closed-loop system for monitoring, evaluating, and improving AI agents in production:- Observe: Capture every interaction your agents have with users through automatic telemetry. See spans, traces, and sessions in real time.
- Score: Attach quantitative verdicts to every interaction. Scores come from automated evaluations, human annotations, or your own custom logic.
- Discover: When scores indicate failures, Latitude automatically groups similar problems into issues: named, trackable failure patterns.
- Evaluate: Generate monitoring scripts from discovered issues. These evaluations run continuously on live traffic, catching regressions before users notice.
- Align: Keep your automated evaluations honest by measuring how well they agree with human reviewers. Latitude tracks alignment metrics so you know when machine judgment drifts from human judgment.
- Simulate: Before shipping changes, run your agent against test scenarios locally or in CI. Reuse the same evaluation scripts that monitor production.
- Improve: Use everything you’ve learned to make your agents better, then repeat.
How It All Connects
Every feature in Latitude feeds the next. Observability captures interactions. Evaluations score them. Failed scores surface issues. Issues generate new evaluations. Human annotations keep evaluations calibrated. Simulations prevent regressions before they reach production.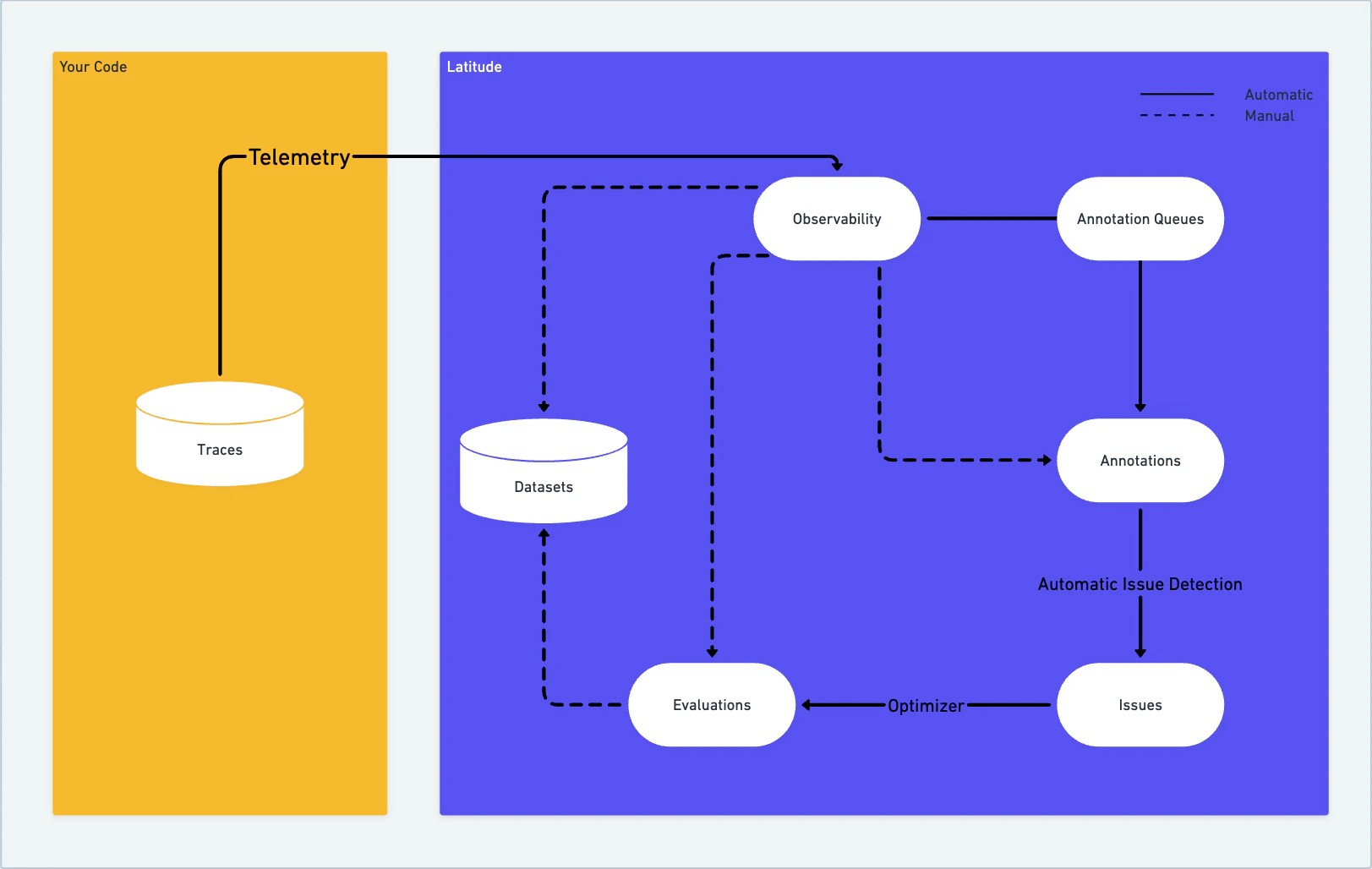
Key Concepts
| Concept | What It Is |
|---|---|
| Span | A single unit of work captured by telemetry (an LLM call, a tool invocation, etc.) |
| Trace | A complete interaction from start to finish, composed of one or more spans |
| Session | A multi-turn conversation between a user and your agent, composed of related traces |
| Score | A quantitative verdict on a trace: normalized between 0 and 1, with pass/fail and feedback |
| Evaluation | A script that automatically produces scores from your agent’s interactions |
| Issue | A named failure pattern discovered by grouping similar failed scores |
| Annotation | A human review of a trace, producing a score through Latitude’s review workflow |
| Annotation Queue | A managed review backlog that routes traces to human reviewers |
| Simulation | A test run of your agent against scenarios, evaluated locally or in CI |
Next Steps
- New to Latitude? Read Core Concepts to understand organizations, projects, and how everything fits together.
- Developers: Follow the Developer Quick Start to connect your first agent and see traces in Latitude.
- Team leads and PMs: Follow the No-Code Quick Start for a walkthrough of the Latitude web UI.